
来源:量子位
本文为约1530字,建议阅读4分钟
本文介绍了清华朱俊彦团队研发的2D草图一键变3D模型并支持实时修改的新AI模型。

CV大佬朱俊彦的新论文,让设计师们感觉危了。
事情是这样的:
微博上搬运了朱俊彦团队的新成果,一个能将2D草图一键变成3D模型的新算法,却意外引发设计圈盆友们的热烈转发讨论。
配文全是“沃日”、“???”……
简单来说,这个模型能让非常粗糙的简笔画,一键变成逼真3D模型。

还支持实时编辑,不满意的地方擦掉重画,立马生成一个新的:

要知道之前的“图转图”模型,基本都是停留在2D层面,这回直接变3D真是一个突破。
也确实是生产力利器。
但没想到,是设计圈先感到了危机。有圈内博主就觉得又要被AI抢饭碗了,随后也有很多人跟转了这一条。
所以论文成果到底说了啥?一起来看。
可从任意角度实时编辑
现在有很多图-图的转换模型,但基本上都是2D-2D。
这是因为从2D到3D,在训练和测试过程中都有很大挑战。
训练方面,想要把2D输入图像和3D输出图像配对,需要庞大数据集,成本会很高。
测试方面,为了得到不同角度的3D模型,需要输入图像的多个视角,但是二者之间可能存在不一致的情况,导致生成效果不好。
为了解决这些问题,朱俊彦团队提出了使用3D神经场景表示(3D neural scene representations)的条件生成模型。
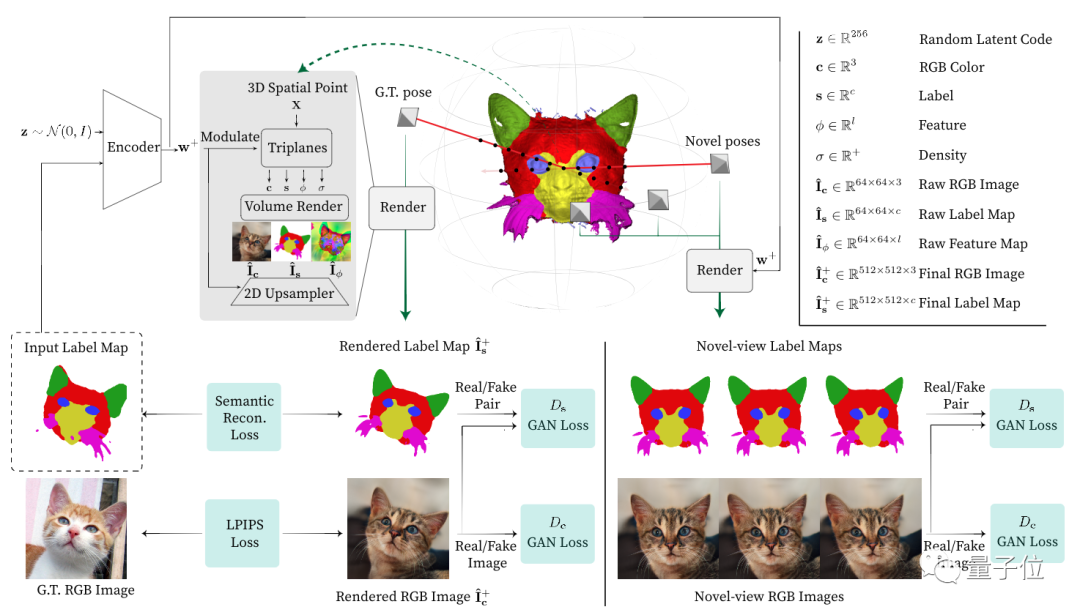
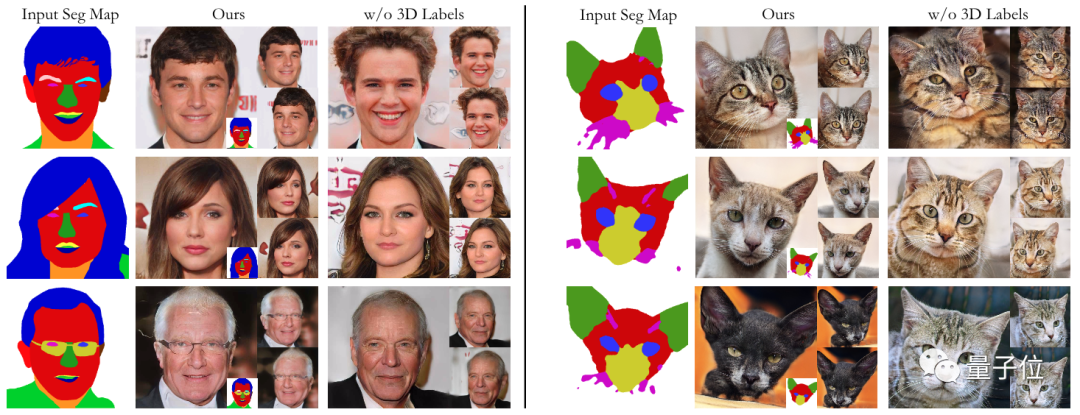
它只需要给定一个2D标签图(如语义分割图和勾线图),能为每个3D点匹配标签、颜色和密度等。实现在渲染图像的同时,像素对齐标签图像。

通过构建一个交互式系统,用户能在任何视角修改标签图,并生成与之相对的输出。
为了实现跨视图编辑,需要将额外的语音信息编码为3D的,然后通过图像重建和对抗损失(adversarial losses)的2D监督,来学习上述3D表示。
重建损失可以确保2D用户输入和相应的3D内容对齐,像素对齐条件鉴别器( pixel-alignedconditional discriminator)也进一步促使外观和标签对应合理,并在新视角时也保持像素对齐。
最后,方法还提出了跨视图一致性损失,强制潜码在不同视点保持一致。
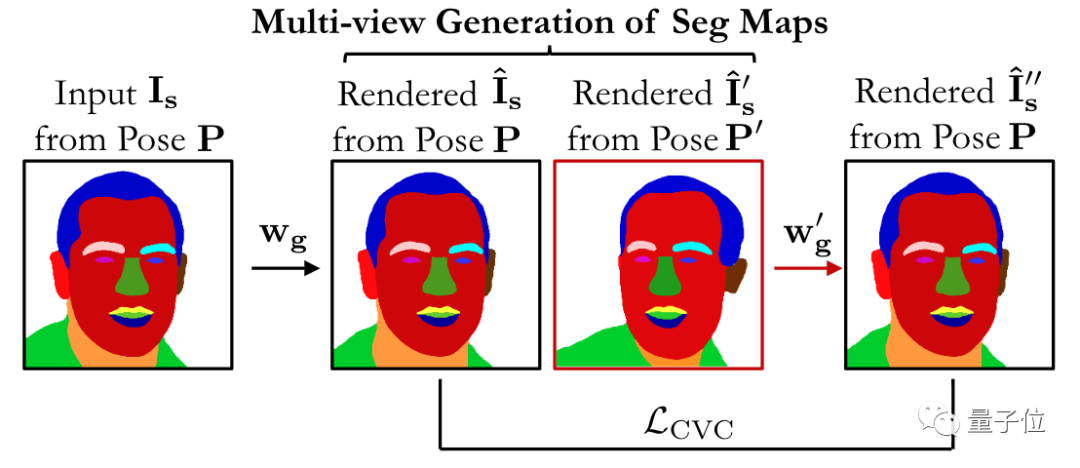
和不同模型对比显示,pix2pix-3D能在保持多视角一致的情况下,生成高质量结果。

消融实验结果同样显示,该方法的生成结果能更好和输入图像对齐。
不过研究团队也提出了方法的一些局限性。
第一,目前它还只能针对于单个对象;
第二,模型在训练过程中,需要与每个训练图像关联相机姿态(camera pose),推理时不需要。如果能不依赖于相机姿态,可以进一步扩大模型的使用范围。
朱俊彦团队出品
该论文成果来自朱俊彦团队。

朱俊彦,现任CMU计算机科学学院助理教授,是AI领域知名的青年学者。
2008年,朱俊彦进入清华大学计算机科学系,学习计算机科学专业。在同专业140人中,朱俊彦排名第2。
2012年清华本科毕业后,朱俊彦奔赴美国,在CMU和UC伯克利经过5年学习,获得了UC伯克利电气工程与计算机科学系的博士学位,师从Alexei Efros。
其博士毕业毕业论文Learning to Generate Images,获得了计算机图形学顶会ACM SIGGRAPH 2018“杰出博士论文奖”。
博士毕业后,朱俊彦来到MIT计算机与人工智能实验室(CSAIL),成为一名博士后研究员。2020年秋季,他回到曾经的母校CMU(卡内基梅隆大学),担任助理教授一职。
曾提出CycleGAN、GauGAN等明星模型。
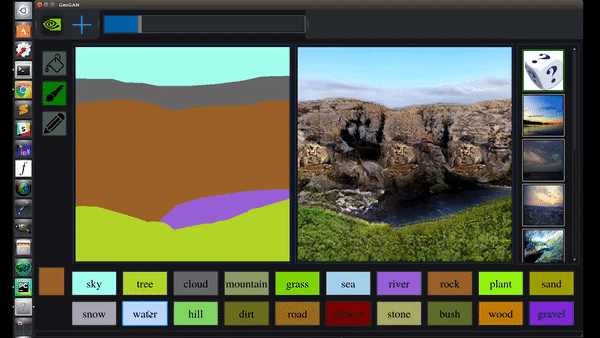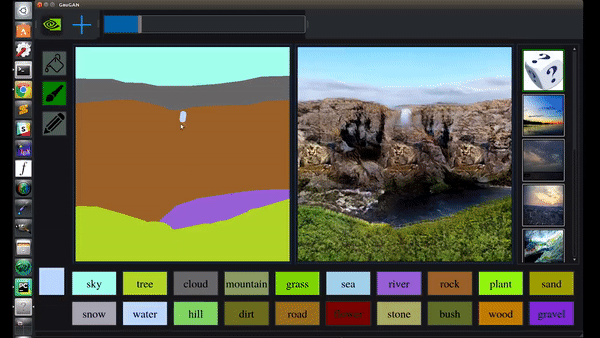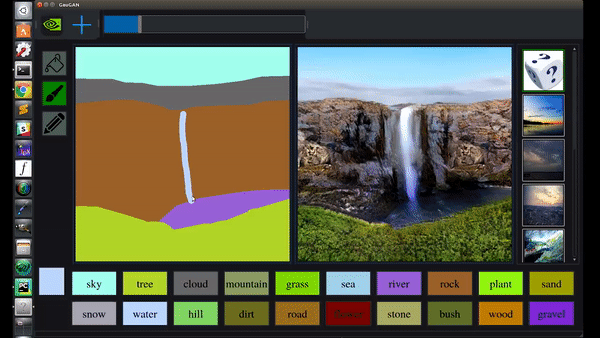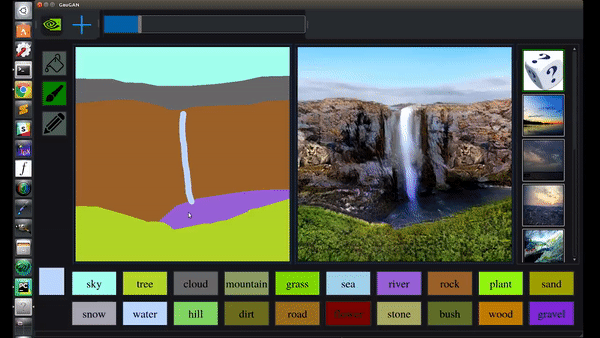 GauGAN支持涂鸦变风景画
GauGAN支持涂鸦变风景画 vid2vid支持从语义图生成真实场景
vid2vid支持从语义图生成真实场景论文一作为Kangle Deng。他现在是卡耐基梅隆大学机器人学院的一名在读博士。他以第一作者身份发表的论文,曾被CVPR 2022、ICLR 2021接收。
 论文地址:https://arxiv.org/abs/2302.08509
论文地址:https://arxiv.org/abs/2302.08509
